An Introduction to IPFS
9 February 2022 - 31 min readNote: as the title might suggest, this article is a bit heavy on acronyms. There is a glossary at the end though, in case you need a refresher on some terms.
What is the IPFS ?
The InterPlanetary File System or IPFS for shorts is a peer to peer network that acts like a distributed file system, allowing storage and sharing of files, data, websites and applications. It is based around a philosophy of modularity, and as such it is actually composed of many independent projects. It is also fully decentralized.
A brief history of IPFS
IPFS was created by Juan Benet, a computer scientist with an interest in distributed systems and peer to peer. In 2013 he got the idea of combining Merkle trees, a data structure used in many distributed systems like Git, with a peer-to-peer file sharing system like that of BitTorrent to create a fully decentralized file-sharing system.
In 2014, he founded Protocol Labs to support his research on IPFS and his startup was incubated at Y Combinator. This allowed him to write a whitepaper that was published later that year and gathered some interest. The project then grew and in 2016 it was split into several parts, with IPFS keeping the higher-level features, InterPlanetary Linked Data or IPLD was assigned the data structures and algorithms, libp2p the more “basic” peer-to-peer applications and Multiformats for futureproof data formats in all three other projects.
From 2017 to 2020, Wikipedia was blocked in Turkey. During that time, an user created a mirror to Wikipedia through IPFS, blocking censorship.
How IPFS can be a better Internet
HTTP has been very useful but still has some issues. It can be quite inefficient when lots of people download the same content, espescially for large files such as YouTube videos. Peer-to-peer allows users to redistribute content between them, resulting in a more efficient spread of the content. The regular web is also quite frail, web pages no matter how popular they are can disappear in an instant never to be seen again, causing data loss. This cannot happen on IPFS where popular files will be replicated in many computers. The web is also very centralized, with concepts of client and servers being extremely present and the presence of many central authorities which threatens the equality of users on the Internet. Finally, in areas where Internet access is difficult or unstable or when big servers are down, or even in the face of censorship, IPFS can provide stability and availability.
It would seem important to address the name of IPFS, because obviously the “InterPlanetary” qualifier is not meant as a joke. Let’s imagine you live on a human base on Mars and need to access data from a server located on Earth. With HTTP, it could take nearly an hour to get a response, even though your colleague just received the exact same data. IPFS in contrast would let your colleague’s computer automatically hear about your request and provide you with the data it received. IPFS lets the Internet work even across heavily partitioned networks !
IPFS Crash Course
On a regular web browser, to access a specific resource, you would use its URL or Uniform Resource Locator which might look like https://www.wikipedia.org/wiki/InterPlanetary_File_System, being composed of a scheme (https), a host (www.wikipedia.org) and a path (/wiki/InterPlanetary_File_System).
It allows you to access a file by specifying its location on the internet, so using an URL is basically telling your web browser “go fetch the item that is located on the top shelf in my bedroom”.
IPFS uses a different method where you specify a content rather than a location. You tell IPFS “fetch me my keys” and it searches them for you. Someone still has to find the location of the item, however you will be able to query it successfully even if it is moved, and provided multiple persons have a copy of it you can get it from whomever you prefer.
To do so, IPFS uses a hash (refered to as the Content IDentifier or CID) of the file you are looking for. A hash is basically an identifier for any piece of data which is derived from the data itself. If you change the data, the hash changes. If you have two items containing exactly the same data, their hashes will be identical.
Once you tell IPFS to look for a CID, it needs to find which member of the network stores the related file. To that end, it uses a Distributed Hash Table (DHT) that links CIDs with the address of a peer storing an instance of the linked file. Great ! Now all you need to do is to send a request to that address and wait for your response !
Find your data in 4 easy steps !
A more straightforward explanation, in case you need it:
- You start with the CID of a piece of data you need to retrieve.
- You query the DHT for a list of nodes near you that can provide the matching file.
- You query one of these nodes using the CID.
- The node replies with the data, which you can hash to ensure it matches your CID.
Peer to peer
IPFS uses a peer-to-peer model. This means that all participants to the network are equals, and can provide and query data equally. In fact, peers will (by default) participate by sharing whatever IPFS data they are storing, acting like a sort of cache. For example, when you query a CID, you implicitly accept to then host that content for some time (after all, you already downloaded it so it is just a matter of telling people they can ask you for a copy). After some time, the file will be removed from your machine automatically by IPFS.
Should you want a file permanently hosted on your machine, you can tell the garbage collector not to delete it by either pinning it or using the Mutable File System (MFS). You can also keep your node from providing non-pinned CIDs with a configuration option.
Immutability
Since a CID is mostly just a hash of a data, knowing that changing anything in the data will lead to a completely different hash, it is easy to see that a CID will always point to the exact same data. This is much unlike the location-based addressing of URLs, and while it means noone can hijack your favorite web page to add malware to it, it also means that when said page is updated, your link still points to the same old version and you now need a new CID.
To solve this issue, IPFS offers pointers. These pointers have a CID, but it does not depend on the data they point to, and as such they can allow the pointed data to change.
Persistence
IPFS aims to increase web pages’ persistence by ensuring files are not deleted as long as they are in use. This is done by having people redistribute CIDs they recently queried, though to ensure a page stays up permanently it is recommended that the page’s owner pins it on his own node. This way there is no need for servers. IPFS uses a garbage collector which regularly frees up the data it considers no longer needed.
Bitswap
Bitswap is the algorithm IPFS uses to exchange data. Files are broken down into blocks which can both contain data and link to other blocks, and each block has its own CID. To request a file, a node starts by sending a want-list, which is basically a list of this file’s block CIDs, to the peers it is connected to. Nodes keep track of their peer’s want-lists, and will send them any wanted block they receive. If none of the peers connected to the node have the CID, the node will then query the DHT itself to find a peer who can provide the block.
Mutable File System
The Mutable File System is an abstraction that lets you manipulate files in IPFS as if they were mutables, which means you can actually edit and delete files in MFS. It allows programmers to have a API very similar to that of any regular file system, with functions to create files and directories, edit and delete them. The MFS will handle everything IPFS-related on its own. Of course if anyone already downloaded the files you placed on the MFS and started redistributing them before you changed the files, the people it will redistribute them to will receive the older version of the file, or will be able to download a deleted file.
Components
IPFS is composed of many modules, here is an overview of the most important ones.
The Multiformats project
If a project is planned to have a long lifetime, it must be built to allow evolution and change without breaking backwards compatibility. To this end, IPFS spawned the Multiformats project with the aim of creating futureproof data formats by making them self-describing, which means a piece of data will contain metadata like its encoding or how it was created. Let’s review the most important ones.
Multihash
You obtain the hash of a value by hashing it, which is to say you run the value through a hashing function. There is not just one hashing function however, there are many, and in the case of cryptographic hashing functions they can become obsolete once people start figuring out how to build a value so that it has a specific hash, after which you absolutely need to change your hashing function quickly to avoid security vulnerabilities.
Therefore, it is crucial for IPFS (which uses cryptographic hashes for many applications) to ensure that it can support many hash functions over its lifetime. The multihash format aims to solve this issue by storing a code representing a hash function alongside the hash. The format of a multihash is as follow:
<hash-func-type><digest-length><digest-value>
with:
- hash-func-type (unsigned variable integer): an unsigned integer of variable size (wait until the next section for more details) which identifies a hash function by its index in a predefined table. The multicodec table is the default table, but you can specify another one yourself.
- digest-length (unsigned variable integer): the length of the hash, in bytes.
- digest-value (hash): the hash itself.
For example 122041dd7b6443542e75701aa98a0c235951a28a0d851b11564d20022ab11d2589a8 is a sha2-256 hash with a length of 32 bytes.
Unsigned varint
An unsigned varint is an unsigned integer of variable size. This means it can represent any unsigned integer regardless of its size, which is useful to ensure you will never run out of space to store an integer. In the aforementionned multihash format it means IPFS will always be able to use new hashing functions without risking running out of IDs in its table, because the table is indexed by unsigned varints which means its size is essentially infinite.
They are encoded from the least significant bit to the most significant bit in increments of seven bits. In each byte of the encoded number, the most significant bit is the continuation bit, set if an only if there is another byte following this one. The seven remaining bits are used to store the binary-encoded number.
To encode a number (for example 37 334) you would convert it to binary (0b1001 0001 1101 0110), reverse the order of the bits (0110 1011 1000 1001), cut it in “packets” of seven bits (0110101 1100010 0100000) then add the continuation bit to each packet (10110101 11100010 00100000, or 0xB5E220).
Multicodec
A multicodec table is simply a table of codecs indexed by unsigned varints, mapping multicodec codes to an encoding system (which itself defines a data type). As long as you have an agreed-upon table, you can ensure that anyone can parse that data appropriately by prefixing it with a multicodec code. To ease the “everyone agrees on a table” part, a default one is provided which is the one IPFS uses. You can find it here. Here are the first few lines of the default table to give you an idea of what it contains (spoiler: not much more than what I told you):
| name | tag | code | status | description |
|---|---|---|---|---|
| identity | multihash | 0x00 | permanent | raw binary |
| cidv1 | ipld | 0x01 | permanent | CIDv1 |
| cidv2 | ipld | 0x02 | draft | CIDv2 |
| cidv3 | ipld | 0x03 | draft | CIDv3 |
| ip4 | multiaddr | 0x04 | permanent | |
| tcp | multiaddr | 0x06 | permanent | |
| sha1 | multihash | 0x11 | permanent | |
| sha2-256 | multihash | 0x12 | permanent |
Multibase
Let’s imagine you need to send a file through a textual messaging system, such as mail, IRC or perhaps a Discord chat. You cannot send the binary file directly, and you cannot simply send it as ASCII because some characters (control codes, the null byte comes to mind) might not be supported properly. Your solution is then to convert your binary file into a text file using only supported characters like digits and regular letters.
To this end, many binary-to-text encodings have been created such as base64 which uses all alphanumeric characters as well as the + and / signs ([A-Za-z0-9+/] if you like regexes) and where each character represents 6 bits of data (2^6 = 64). The issue that arises from that is obviously that when receiving such text-encoded binary data, one might not know what the encoding is. Provided the text fragment is long enough one might be able to infer the set of all characters used in the encoding scheme, but there might still be several encodings using the same set of characters and which assign different values to the same character.
Multibase is a protocol that lets you add a layer of encoding in which you prefix your encoded data with a single character identifying a single binary-to-text encoding. For example, the character ‘m’ denote base64, a ‘f’ denotes hexadecimal and a ‘z’ denotes base58. Do note that there is only one multibase table, it is not a default table like the multicodec table, probably because there are far fewer encodings than data types.
Here is the current multibase table, with only the default (permanent) entries. See here for the full table.
| encoding | code | description | status |
|---|---|---|---|
| identity | 0x00 | 8-bit binary (encoder and decoder keeps data unmodified) | default |
| base16 | f | hexadecimal | default |
| base16upper | F | hexadecimal | default |
| base32 | b | rfc4648 case-insensitive - no padding | default |
| base32upper | B | rfc4648 case-insensitive - no padding | default |
| base58btc | z | base58 bitcoin | default |
| base64 | m | rfc4648 no padding | default |
| base64url | u | rfc4648 no padding | default |
| base64urlpad | U | rfc4648 with padding | default |
Content ID
A Content ID or CID is an identifier for a piece of content, like a file or part of a file, and in IPFS it acts as an equivalent to Internet’s URLs. It is essentially a hash of the content it refers to, but to ensure upgradability and futureproofing it is self-describing and relies heavily on the other multiformats presented in this section.
There are currently two types of CIDs as well as a special human-readable format, and CIDs can be stored in both binary and text format.
Human-Readable CID
The human-readable form of a CID looks like this:
<hr-mbc>-<hr-cid-version>-<hr-mc>-<hr-mh>
with:
- hr-mbc: the multibase code
- hr-cid-version: the CID version
- hr-mc: the multicodec code for the multihash’s encoding
- hr-mh: the multihash Obviously each of these components must be in a human-readable format themselves.
CIDv0
The first version of the CID standard is simply a base58-encoded multihash, and although they might seem rudimentary they are still in wide use, being the default version generated by many operations to this day. They are always 46 characters long and start with Qm if encoded as a string, and 32 bytes starting with 0x1220 when encoded as a number.
For example, QmY7Yh4UquoXHLPFo2XbhXkhBvFoPwmQUSa92pxnxjQuPU is a CIDv0 multihash with the human-readable format base58btc-cidv0-dag-pb-(sha2-256:256:9139839E65FABEA9EFD230898AD8B574509147E48D7C1E87A33D6DA70FD2EFBF).
CIDv1
CIDv1, in contrast, is the first version of the CID standard which includes a version number, allowing the standard to evolve further. It follows the format:
<mb-prefix><cid-version><mc-ct><mh-ca>
with:
- mb-prefix (multibase code): the multibase prefix
- cid-version (unsigned varint): the CID version (here 1)
- mc-ct (multicodec code): the format of the data referred to by the CID
- mh-ca (multihash): the hash of the referred data.
So when you try to decode a CID, you first check if the format matches the CIDv0 format and then if it does then you implicitly know the encoding. Otherwise you read the base prefix to know how the rest of the data in encoded. Using said encoding, you then check the CID version number and find that it is a CIDv1 (any other value would currently be invalid). Then you would read the multicodec code, which should confirm that you are indeed decoding a CID (up until now you could have been decoding any multicodec-supported type of data, for example an IP address or a raw multihash). Finally, you would decode the multihash which is the core of the CID.
For example, bafybeierhgbz4zp2x2u67urqrgfnrnlukciupzenpqpipiz5nwtq7uxpx4 is a CIDv1 multihash with the human-readable format base32-cidv1-dag-pb-(sha2-256:256:9139839E65FABEA9EFD230898AD8B574509147E48D7C1E87A33D6DA70FD2EFBF).
libp2p
libp2p is a modular collection of peer-to-peer protocols, specifications and implementations allowing programs to find peers and connect to them to retrieve data, created to answer the lack of proper tools and standards in the peer-to-peer world, where every actor would pretty much reimplement the same algorithms and the code reuse was very small. It was initially part of IPFS but was eventually modularized out of it and is now a completely independant project which is not used solely by IPFS. For example, one of the “official” server implementations (Dendrite) for the decentralized peer-to-peer Discord equivalent Matrix uses libp2p.
The two most complete implementations are currently written in Go and JavaScript (for native and browser), though a Rust implementation is making good progress. While it performs most of the heavy lifting in IPFS, I will not talk about it in detail apart from one of its most interesting features.
Publish/Subscribe
Publish/Subscribe is a system that allows peers to subscribe to a “topic” they are interested in, allowing them to be notified every time there is an update on this topic. This can be used for example for chat rooms or file sharing. Let us now take a look at the main publish/subscribe implementation, Gossipsub.
In Gossipsub, there are two types of links between peers: full-message and metadata-only. You could interpret this as having two networks sharing all nodes but no edges, where the metadata-only network would have a lot more links than the full-message one.
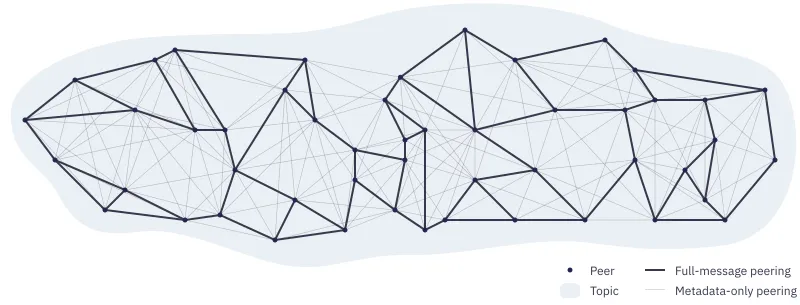
A network is made up of two types of links
The full-message network (also called the mesh), as the name implies, focuses on transmitting the full content of messages throughout the network. This is the reason why it is kept sparse: having too much redundancy would generate much more traffic than necessary. To ensure sparsity without growing so thin it could fail though, the network maintains a target number of full-message peers for each node (its network degree). When a peer wants to send a new message or when it receives one, it stores it and sends a copy to each of its full-message peers.
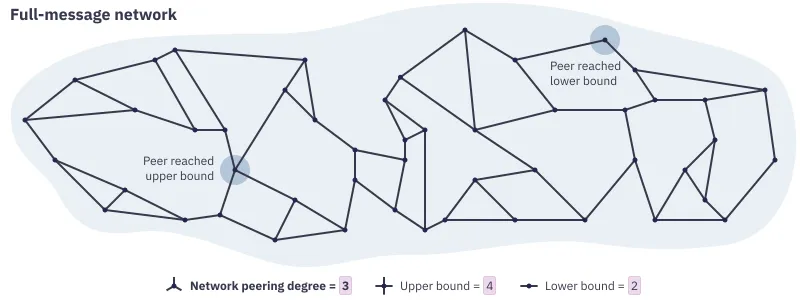
A network with degree 2/3/4
The metadata-only network only shares “gossips” (hence the name Gossipsub) about which messages are available, where peers regularly (every second for example) gossip by randomly choosing some of their peers and telling them about the messages they recently heard about. Because a gossip is much lighter than a full message (a gossip is a message’s metadata, hence the name metadata-only) this network is allowed to be much more densely connected. Gossiping lets peers know if they regularly miss out on messages, in which case they might need to change their full-message peers to more reliable ones.
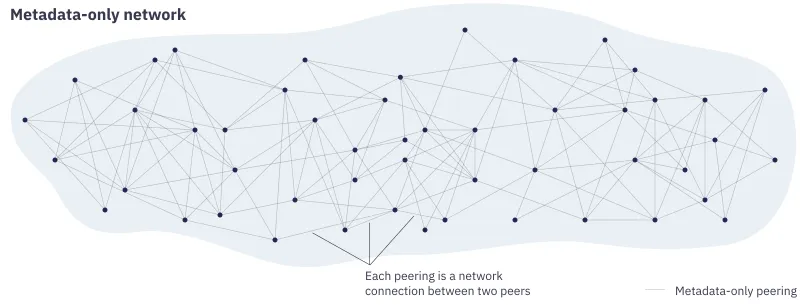
An example of a metadata-only network
Peers regularly check their number of full-message peerings (every second by default) and if needed they will either upgrade metadata-only connections to full-message (this is called grafting) or turn full-message connections into metadata-only (called pruning).
Peers keep track of their connected peer’s subscription lists.
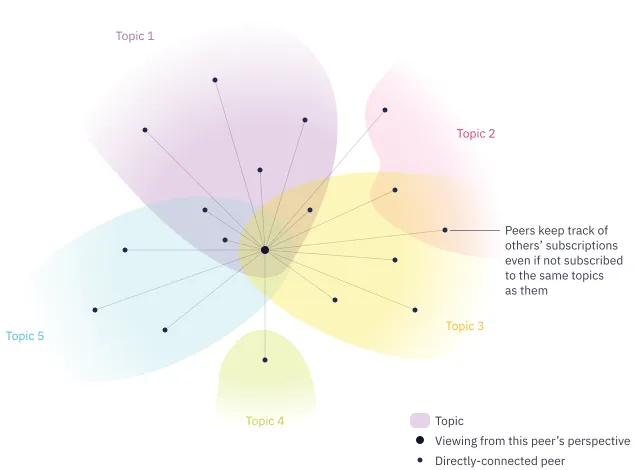
A peer’s vision of its surroundings
To subscribe to a new topic, a peer grafts its connections with peers who are already subscribed to this topic. Conversely, a peer will prune its connections to peers subscribed to a topic when it wants to unsubscribe from it.
IPLD
InterPlanetary Linked Data is basically the specification for IPFS’s decentralized data structures and algorithms library, built on top of libp2p. While it defines many algorithms, we will only take a look at the one IPFS uses most, along with IPLD’s main data structure.
The IPLD Data Model
The IPLD Data Model is the data type manipulated by IPLD’s algorithms. It is conceptually similar to JSON being composed of blocks that can be nested and primitive type, but with a few new types like links (which are CIDs) and raw binary data.
Data models can be represented in many formats like JSON or CBOR, the Concise Binary Object Representation which resembles JSON but is encoded as binary rather than text for a smaller footprint. Of course when in a serialized form data models are prefixed with a multicodec code.
Merkle DAGs
Merkle DAGs (or hash trees) are Directed Acyclic Graphs where each node can contain some data and is labeled with the hash (a CID) of its children’s labels concatenated to the block of data. So to get the label of a node, you take the data (if any) that it contains, concatenate it to each of its children’s labels, then hash it all to get a CID. When you change a leaf its hash changes which in turns changes its parent’s hashes and so on. In the end, the leaf and all its parents are assigned a new CID. The old CIDs are still around though, which means Merkle DAGs are immutable data structures. If you know how immutable lists work, they are very similar. Since a CID can identify a single node with many children, a single CID can link to many different but related pieces of data, effectively becoming directories.
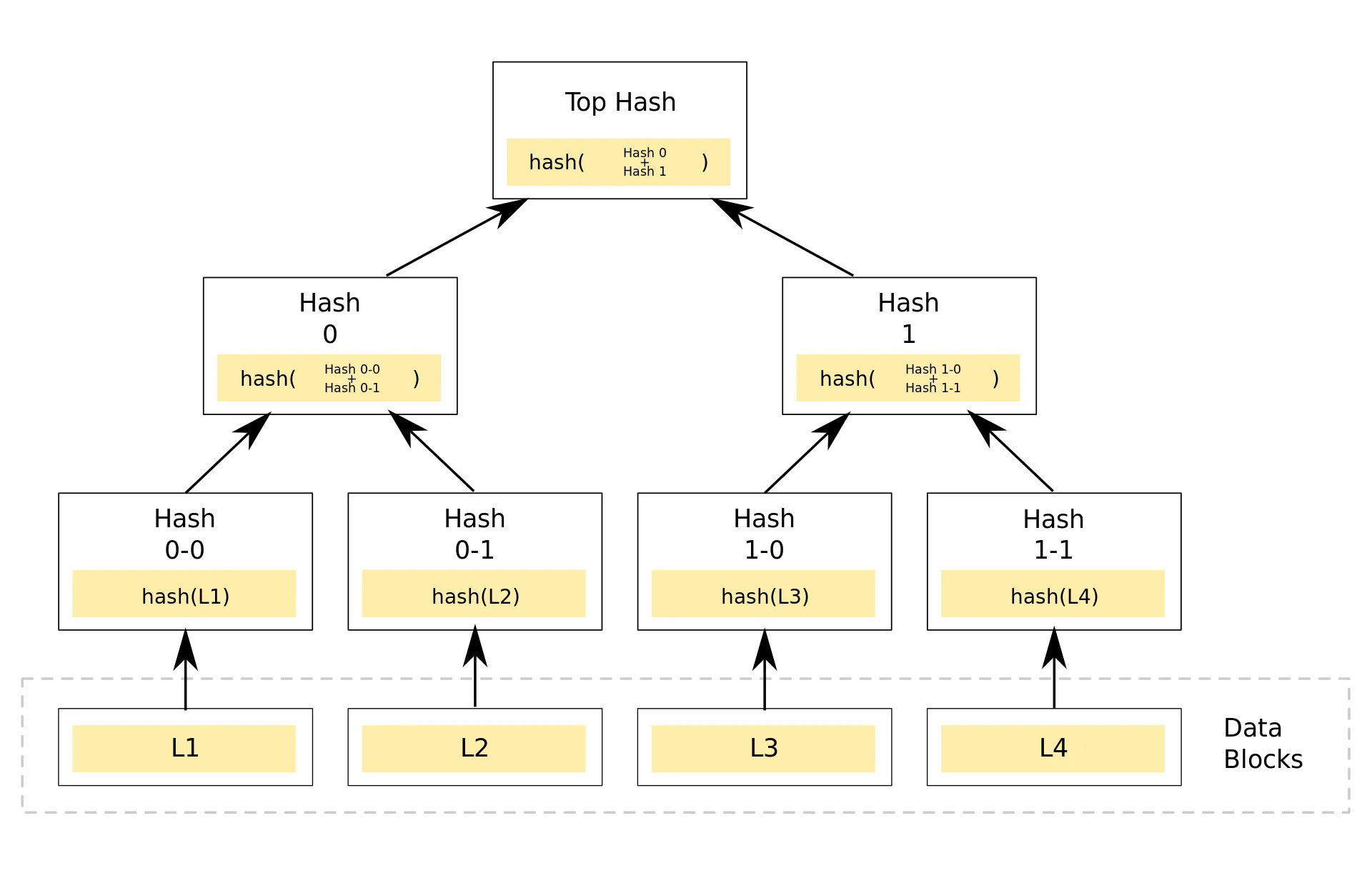
An example of a hash tree (Source)
DAGs are widely used in distributed systems (eg. Git) because they are by nature recursive: every node is the root of its own small DAG. This makes it easy for a single peer to store only smaller parts of the global DAG since they can choose a root node and only store it and its children. It is also easy to retrieve subtrees because they can be represented with only the root node’s CID and the operation can be easily parallelized. It also helps reduce duplication, since two pieces of data with the same content would have the same CID, which is easy to notice since CIDs are hashes. IPFS then knows it only needs to store a single piece of data. For websites with a lot of duplicated content (especially pictures and CSS), this means IPFS can detect when not to download files twice and make network usage more efficient.
Kademlia
Kademlia is the name of an algorithm that creates and queries distributed hash tables. It assigns a (mostly random) number to each node called a node ID to act as a “position”, from which it can derive a distance between two nodes with a logical XOR -physical distance is not taken into account. Every message sent by a node contains its node ID so that the recipient can add it to its records if necessary, and nodes randomly query themselves on the network to discover their surroundings. Keys are the same size and format as node IDs (which are CIDs), and files are stored in the nodes closest to their key so finding a file is a matter of finding the closest node to that file.
XOR as a distance function
First, a reminder of how a distance function is defined. A distance function is a function where is a set. To qualify as a valid metric, a function must have the following properties for :
- : two elements are equal if and only if their distance is zero.
- : a distance function must be symmetrical, the distance is the same from both ends.
- : a distance function must respect the triangular inequality, in other words a direct path cannot be longer than an indirect one.
One of Kademlia’s most important innovations is its use of the XOR function as a metric (XOR as in the exclusive OR of all bits of the two operands). Let us verify that XOR is indeed a distance function.
-
The first property should be self-evident. XOR returns 0 if and only if both bits are equal.
-
Symmetry should not be a problem either, the truth table of the XOR function is symmetrical.
-
Triangular inequality a little more difficult. We should note that a XOR function’s result is equal to the sum of its operands if they share no power of two in their decomposition and less than it if they do ().
Another property to note is that since XOR is associative () and commutative () along with we can deduce .
By combining these properties we see that and thus triangular inequality is respected.
A particular property of XOR as a distance function is that it is unidirectional, which means that there is only a single point that is at a given distance of a given point. In other words, if you take a point and look for all points at a distance to , you will only ever find a single point.
As an example, here are the XOR distances to five for number from 0 to 9:
| Number | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| Distance | 5 | 4 | 7 | 6 | 1 | 0 | 3 | 2 | 13 | 12 |
Contact information storage
A Kademlia node stores contact informations about its peers to perform routing. To be able to perform routing, a Kademlia node stores contact informations (IP adress, UDP port, node ID) about its peers. These contact informations are stored in lists called k-buckets, with one k-bucket for each bit of the node IDs. A Kademlia table is therefore parameterized by the bit size of its keys (which is the number of k-buckets) and the number of peers to keep in each k-bucket, respectively 256 and 20 in IPFS for example.
The ith k-bucket only contains peers with a distance to the node comprised between 2i and 2i+1, which is equivalent to having the same first i bits as the node in their key. Additionally, k-buckets are sorted by time since the node was last seen to place the most recently seen nodes at the tail. If a k-bucket is full and a node which would fit in that k-bucket is discovered, the least recently seen node in the k-bucket is pinged. If it fails to answer, it is replaced by the new node. Otherwise the new node is discarded.
This obviously means that older nodes are favored over younger ones, and the reason for it is that there is statistical evidence that the longer a node has been connected to a peer-to-peer network, the higher its likelyhood of staying online for a while longer. These stable nodes are very useful in a decentralized network because they can act as anchors, reliable places to find connections. Thus nodes try to keep nodes with the longest uptimes in each bucket. Also note that live nodes will never be removed from a bucket, which makes DoS attacks more difficult.
Node lookup
Let us imagine we are a node of address A which needs to find a node of address B. The first thing we should do is to find amongst all the nodes in our buckets the ones with the smallest distance to B. We ask these nodes for the closest nodes they know of to node B (this happens in parallel). As we receive results, we send more queries which allows us to get incrementally closer to node B. If we ever stop getting better results from further queries, it will mean that node B is not on the network.
The reason why results get better is the usage of k-buckets and the XOR metric. The XOR metric being unidirectional means that you cannot find a different node with an equal distance to one you already found. k-buckets being buckets where the first k-bits of the node’s IDs are the same as the current node means that a node stores more contact information about nodes close to iself, meaning nodes know their surroundings very well. Thus at every query we should be able to get at least one bit closer to our destination, resulting in a logarithmic number of queries.
IPNS
To deal with the issue of updating web pages in an immutable system, IPFS uses the InterPlanetary Name System, or IPNS. It allows creating addresses that can be updated. These addresses are the hash of a public key and are associated with informations on the hash it links to that is signed by a corresponding private key. It is then possible to query IPNS for the page associated to an address. If MFS allows you to update your node’s file system, IPNS is what allows others to see the updated files.
IPFS’s future challenges
While IPFS certainly works as a proof of concept, there are still many issues to take care of before it can actually scale up to a widely used Internet protocol.
Privacy
IPFS is a public network, which means anyone can “listen” to what happens on it. Anything you do on this network, much like with standard HTTP, is trackable and loggable. IPFS could try to anonymise you, but this would require adding more to the core protocol rather than being an optional extension, and thus go against the principle of modularity. Such features would also be quite generalistic, and might force those looking for more privacy to build around these built-in privacy features in order to add their own, making it potentially more difficult.
Monitoring
It is possible to monitor IPFS traffic to know who requested which CIDs and when they did similarly to plain HTTP with URLs although there are experiments on the usage of Tor to access IPFS to alleviate this issue.
Redistributing content, however, will always lead to your node warning its peers that it contains a CID and writing an entry to the DHT, thus indicating you either pinned it or accessed it recently. It is possible to disable content redistribution but obviously the network cannot work if noone is willing to act as a content provider.
Finally, data transferred between nodes is unencrypted by default, although this behavior can be modified so that one would have to know which CIDs the receiving node previously requested to guess the content of the transferred data.
Data encryption
Since files can be requested by anyone, there is no real way to restrict access to sensitive files other than to place them on the network pre-encrypted, so that only the encrypted file will be on the network. This is not a perfect solution by any means though, since anyone can request the encrypted files and perhaps more importantly the files will be very hard to remove from the network, creating very high risks should the method used for encryption ever be compromised. Other solutions are being worked on and should eventually come to fruition as the need for encryption on IPFS grows.
IPFS Gateways
There are public IPFS gateways that can act as proxies for your queries. You can send queries via HTTP, and the gateway will make the actual IPFS query for you. This way, you do not need a local node and are not part of the network. Content that you requested will be visible on the DHT, but associated with the gateway and it will not be possible to link it to you. Gateways, however, are more intended as a bridge with the “regular” web to help legacy code with using IPFS.
Much like with VPNs, the gateway can however collect informations about your requests.
Private networks
It is possible to build private IPFS networks which can only be accessed by authentified and trusted peers. This will, however, largely cancel IPFS’s scaling abilities since there will be fewer peers to ensure the continuous availability of content. Apart from that, a private IPFS network will behave much like a company’s intranet.
NATs are evil
Network Address Translation is a technique commonly used in networking by Internet Service Providers. It basically consists in having your Internet router “hide” your local network. External machines will only see you router and won’t know what other machines are hidden behind it. This allows your ISP to only give you a single IP address (for your router) rather than one for each of your devices.
However, if you ever tried to set up a Minecraft server in the past, you have probably been faced with one of NAT’s issues: hosting content on your computer becomes much more complicated since other machines cannot see your computer. This problem can be solved using port redirection (which tells your router to send specific packets to your computer rather than refusing them), but it is not something that can be expected of the average user.
Indeed if NATs would prevent you from hosting a server for your favorite game, they will certainly prevent you from acting as a host for any IPFS content. Thus, unless you take specific measures to ensure you can redistribute content, other peers will not be able to contact you. While libp2p includes some utilities to detect NATs and set up automatic port redirection on some routers, this might not be enough to let IPFS thrive in a heavily NATted Internet.
Final thoughts
While I don’t think IPFS is currently able to replace the “centralized” web or even if it will ever reach such a state, I do think the many challenges faced by IPFS’s creators were worth solving. Projects like IPLD, libp2p and espescially Multiformats are offering solutions to problems many developers have been facing in the past and will be faced with again in the future. In a world where a few gargantuan companies’ control over Internet grows more concerning every day, there is definitely value in making sure their vision of Internet is not the only viable one.
Glossary
There are a lot of acronyms around IPFS. Here are some of them.
- IPFS (InterPlanetary File System): If you haven’t got this one, you might have missed the fact that english is read from top to bottom.
- CID (Content Identifier): It is… an identifier. For content. It identifies content. Basically it is the hash of a file, and thus a designator for that file.
- IPLD (InterPlanetary Linked Data): a library for decentralized data structures and algorithms.
- DAG (Directed Acyclic Graph): An oriented graph with no cycled in it. This means that the graph flows from its “root” nodes to some “leaf” nodes. It could look like a tree where some branches have more than one parent. Merkle DAGs are DAGs where each node has an unique identifier based on its content and its parents, in our case each node has a CID.
- DHT (Distributed Hash Tables): a hash table that is split across the members of a network. A hash table is a data structure that lets you retrieve items quickly for as long as you know their key, which acts as an identifier.
- Metadata: Data about the data. A piece of data linked to another piece of data and which describes it. For example, you might have a file (your data) and informations related to this file such as its name, size, last modification date and type (.exe, .pdf, .txt).
- PeerID: an identifier tied to a node of the network.
- VPN (Virtual Private Network): don’t you watch videos on Youtube ? How do you not know about these ? A VPN is basically a proxy that will perform your internet requests for you. This way, noone will know which websites you visited… Except the VPN provider himself. It’s like asking someone to ask for something for you. To the public, your proxy is the one who made the request, but the proxy still knows you are the one who wanted that data.
- libp2p: the network stack used by IPFS, which is its lowest level component. Its task is establishing connections between peers to allow data transfer.
- encoding: the way data is stored in a medium. For an unsigned integer stored as text, you could encode it using its binary (0b00101010), decimal(0d42) or hexadecimal (0x2a) representation. To store text as numbers, you could use ASCII or UTF-8 for example.
- base58: an encoding that uses alphanumeric characters (digits, lowercase letters, uppercase letters) with a 58 radix to store numbers. You might notice that things do not quite add up though: there are 26 lowercase letters, just as many uppercase and ten digits. That sums to 62 characters, not 58. This is because characters 0, O, l and I (zero, uppercase ‘o’, lowercase ‘l’ and uppercase ‘i’) are left out due to often being too visually similar.
- Peer: a member of a decentralized network.
- DAG (Directed Acyclic Graph): A graph (nodes and links between two nodes) where the links between nodes have a direction (they are not bidirectional) and there is no cycle (given a node N, it is impossible to build a non-empty path that would start on N and end on N).
Sources
- IPFS official documentation
- This article about privacy in IPFS
- The IPLD docs and specs
- libp2p official documentation
- https://proto.school, a website with tutorials about IPFS concepts and usage
- The Multiformats website (for most multiformats)
- Unsigned varints only have a github page
- The Kademlia paper
- https://www.wikipedia.org/ (probably)
Other resources
Graphics from the Publish/Subscribe section taken from the official libp2p documentation.